
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- Facial Landmark Localization
- VQ-diffusion
- VQ-VAE
- Markov transition matrix
- Face Pose Estimation
- ENERGY-BASED MODELS FOR CONTINUAL LEARNING
- PnP algorithm
- Energy-based model
- Face Alignment
- L2P
- Class Incremental
- Vector Quantized Diffusion Model for Text-to-Image Synthesis
- state_dict()
- timm
- 베이지안 정리
- requires_grad
- Mask-and-replace diffusion strategy
- CIL
- mmcv
- CVPR2022
- DualPrompt
- learning to prompt
- img2pose: Face Alignment and Detection via 6DoF
- Img2pose
- Discrete diffusion
- Class Incremental Learning
- prompt learning
- Mask diffusion
- learning to prompt for continual learning
- Continual Learning
Archives
- Today
- Total
Computer Vision , AI
[One-page summary] MetaFormer Is Actually What You Need for Vision (CVPR 2022) by Yu et al. 본문
Paper_review[short]
[One-page summary] MetaFormer Is Actually What You Need for Vision (CVPR 2022) by Yu et al.
Elune001 2024. 1. 16. 00:58● Summary: The performance of a transformer comes from its architecture, not the attention module
● Approach highlight
- MetaFormer: The structure of the transformer plays a bigger role in performance than the type of token mixer

- PoolFormer: Prove that the structure of the MetaFormer has a greater impact on the performance of the transformer by replacing the token mixer with a pooling layer to validate performance.
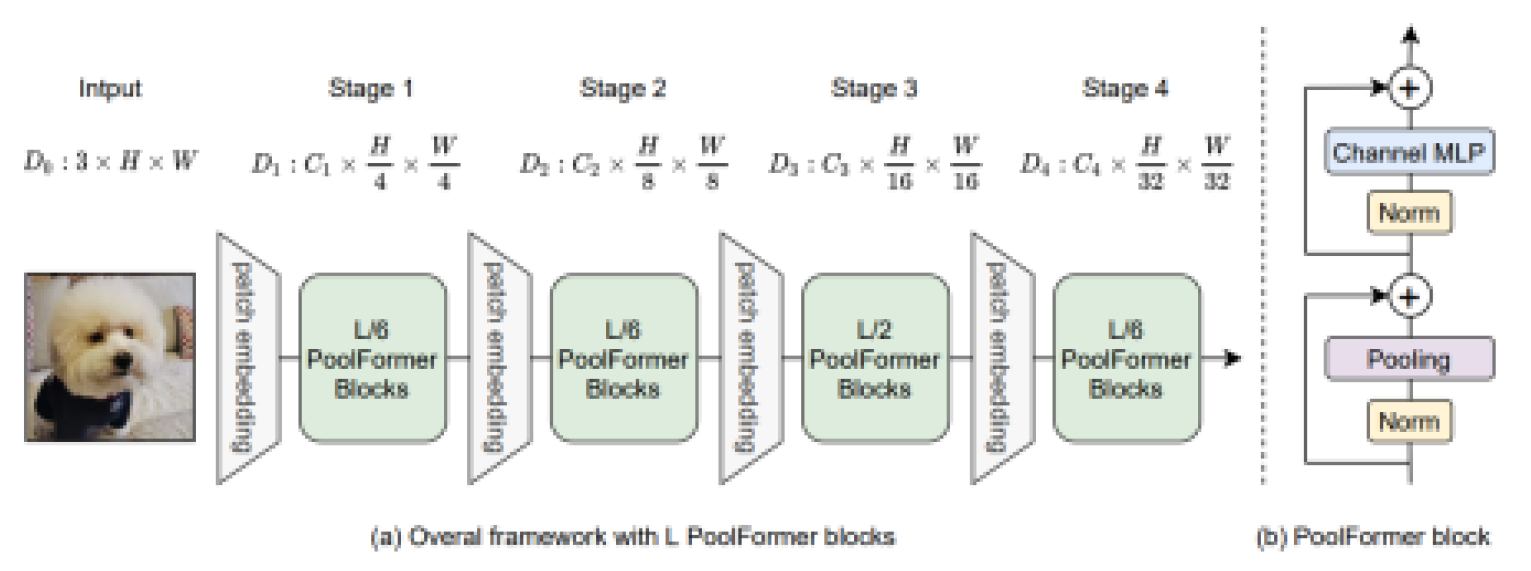
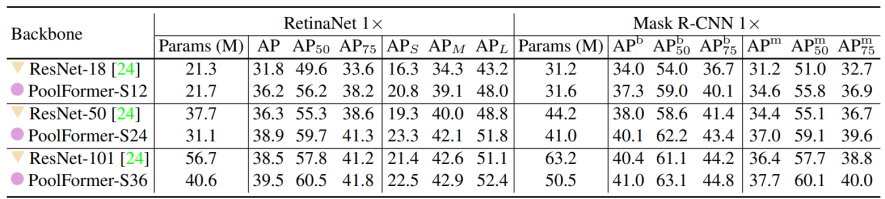
● Main Results:


● Discussion
- The reason why the proposed method(PoolFormer) doesn't work NLP tasks.
'Paper_review[short]' 카테고리의 다른 글
'Paper_review[short]' Related Articles
more



