
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- VQ-VAE
- 베이지안 정리
- ENERGY-BASED MODELS FOR CONTINUAL LEARNING
- Vector Quantized Diffusion Model for Text-to-Image Synthesis
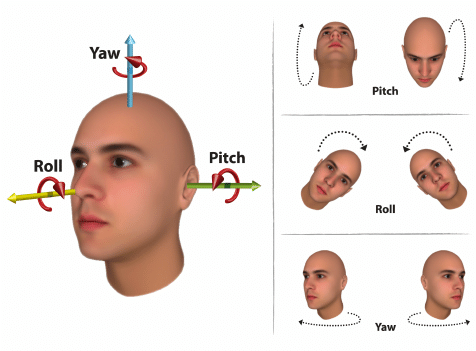
- Face Pose Estimation
- DualPrompt
- Mask-and-replace diffusion strategy
- Face Alignment
- timm
- learning to prompt
- Continual Learning
- Class Incremental Learning
- Facial Landmark Localization
- PnP algorithm
- CVPR2022
- Img2pose
- Discrete diffusion
- VQ-diffusion
- L2P
- Energy-based model
- mmcv
- CIL
- learning to prompt for continual learning
- Class Incremental
- requires_grad
- prompt learning
- img2pose: Face Alignment and Detection via 6DoF
- Markov transition matrix
- Mask diffusion
- state_dict()
- Today
- Total
Computer Vision , AI
img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation, CVPR 2021 논문 리뷰 본문
img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation, CVPR 2021 논문 리뷰
Elune001 2022. 11. 8. 21:46Facebook AI에서 2021 CVPR에 발표한 face pose estimation model
- 특징
1. 기존 face pose estimation model들의 경우 얼굴이 먼저 검출됬다는 가정하에 검출된 얼굴을 입력으로 받아서 pose estimation을 진행하는데에 비해 img2pose는 전체적인 img를 집적적으로 입력받아 face들의 pose를 estimation함
2. local frame과 global frame 사이의 효과적인 pose conversion 방법을 제시
3. bounding box prediction 없이 6DoF 정보만을 가지고 최소한의 computational cost를 가지고 bounding box를 생성해냄
4. facial landmark localization 없이 face에서 직접적으로 pose를 estimation을 하여 68개의 landmark를 사용하는 모델들에 비해서 작은 얼굴들에 대해 좀더 좋은 예측성능을 낼수있다고 주장함(?)

- 용어, 기본 개념 설명
6DoF(Degree of Freedom)
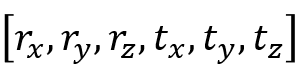
3DoF(yaw, pitch, roll) rotation에 x, y, z translation을 추가하여 6DoF라고 정의함
Intrinsic matrix (카메라 내부 파라메터)
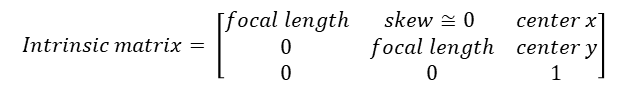
일반적인 pinhole camera를 기준으로 하는 카메라 내부파라메터 image plane으로의 mapping을 위해 필요함
Extrinsic matrix (카메라 외부 파라메터)
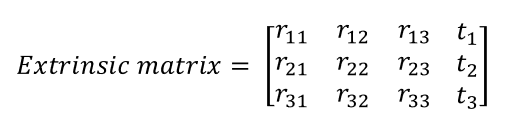
피사체의 rotation가 translation 정보가 담겨져있음 real world 3D coordinates 의 2D projection을 위해 필요
World coordinate to image plane matching
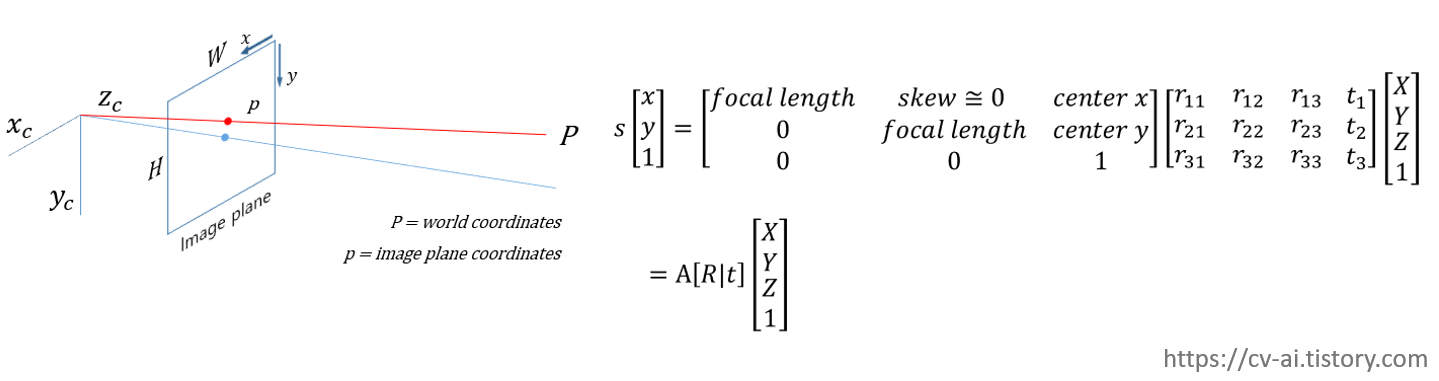
메인 내용이 image geometry가 아닌고로 간단하게 언급하고 넘어가면
3차원상의 world coordinate가 있다고 했을 때 rotation translation정보가 담긴 extrinsic matrix를 matrix multiplication을 해줘서 center로부터 1m만큼 뒤에 떨어진 위치에 2D coordinates로 projection시킨다.
이후 digital영상으로 이를 다루기 위해 camera의 내부파라메터(intrinsic matrix)를 matrix multiplication를 해주면 해당 좌표를 image plane상의 2d coordinate로 보낼 수 있다.
구체적인 내용이 궁금하신 분은 밑에 링크를 참조하면 좋을 거 같다
https://darkpgmr.tistory.com/82
- 본론
Architecture
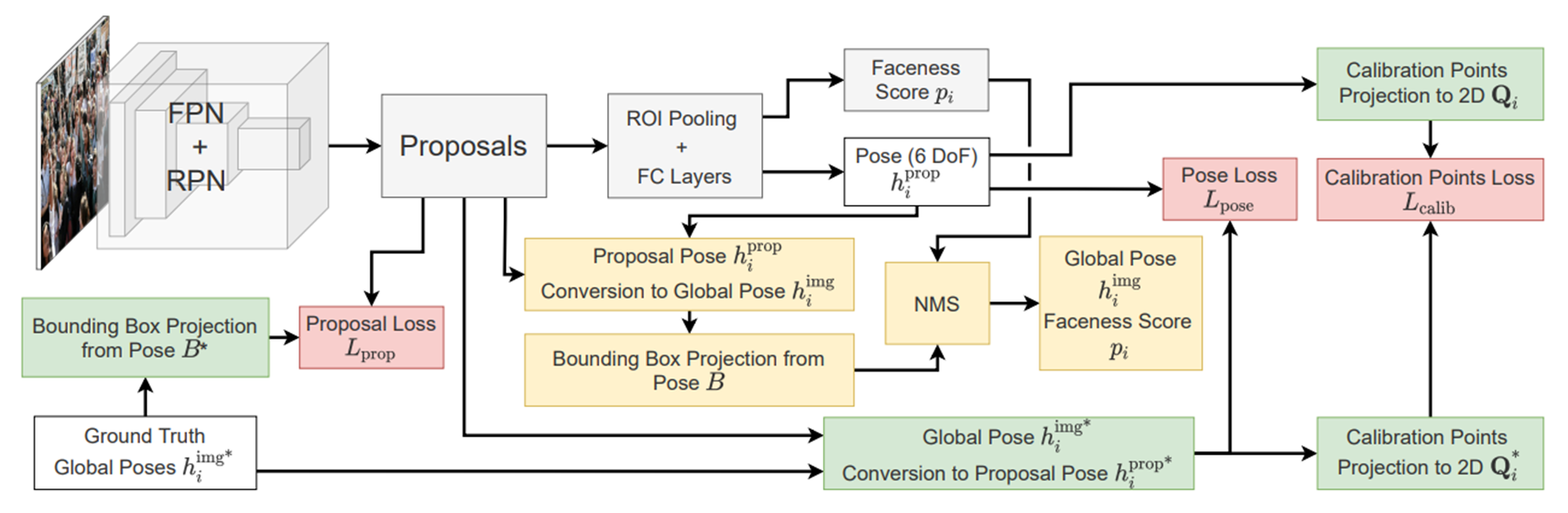
사실 뭐 거창하게 설명할 내용이 없긴하다. 핵심은 local과 global pose간의 conversion 부분이고 구조는 faster rcnn의 구조를 그대로 따른다. 다른 점이 있다면 6DoF pose로 bounding box를 만들거기 때문에 얼굴인지 아닌지를 판단하는 Faceness head와 6DoF를 예측하는 pose head만 있을 뿐 bounding box offset을 예측하는 detection head가 없다.
Local to global pose conversion
일반적인 CNN기반 2 stage detector를 기준으로 head는 proposal에 해당되는 feature를 RoI pooling하여 받게 된다.
이렇게 받게 된 proposal에는 이미지 전체에 대한 feature가 들어가 있지 않을 수 있고 (물론 receptive field에 따라 다를 수 있다) 해당 proposal이 이미지 상에서 어디에 위치하는지에 대한 정보도 없다.
따라서 head가 proposal만을 보고 이미지 전체에서 이 얼굴이 어디에 놓였는지 판단하기는 힘들기 때문에
proposal영역 내에서의 pose인 local pose를 예측하고 local pose를 global pose로 변환하는 과정이 필요하다고 할 수 있다.

상기 algorithm을 통해 local to global pose conversion을 진행하는데 식이 복잡해보일 수 있지만 생각보다 아주아주아주 간단하니 차례대로 한번 따라가보도록 하자
1. depth 조절
보통 제대로된 bounding box가 잡혔다는 전제하에 bounding box를 기준으로 crop된 이미지를 생각해보자
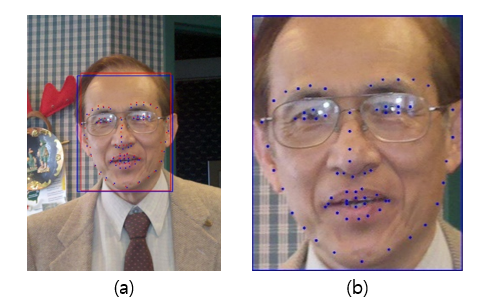
(a)는 이미지 전체 (b)는 bounding box를 기준으로 crop된 이미지이다.
(b)의 경우 실제로는 crop된 이미지이지만 crop된 이미지만 봤을 때 피사체와 camera 사이의 거리가 가깝게(t_z가 작은) 찍힌 영상이라고도 생각할 수 있을 것이다.
우리가 pose head를 통해 예측한 local pose의 경우 (b)를 기준으로 하는 pose이기 때문에 이미지 전체를 기준으로하는 global pose를 만들기 위해서는 먼저 이 t_z를 이미지 전체의 scale에 맞게 zoom ou해주는 과정이 필요하다.
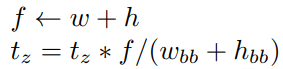
f: focal length
w, h: 원본 image의 width, height
t_z: 카메라와 피사체 사이의 거리, depth (bounding box기준)
w_bb, h_bb: boundingbox의 width, height
따라서 bounding box와 원본 image 전체의 길이에 비례해서 zoom out을 해줘서 focal length를 맞춰준다.
2. global pose구하기 (x, y, z translation)
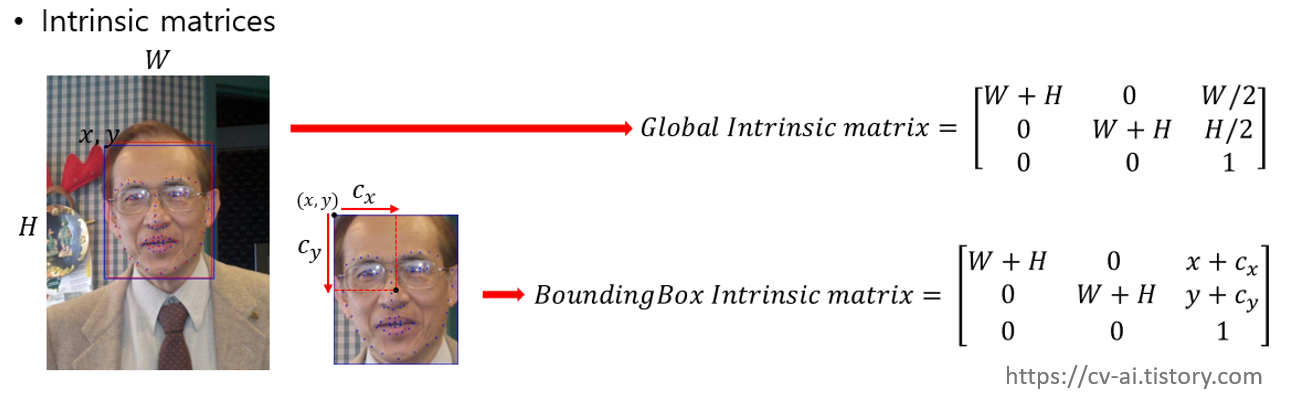
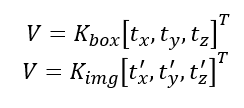
K_box, K_img: boundingbox기준으로 봤을때의 intrinsic matrix, 이미지 전체를 기준으로 봤을때 intrinsic matrix
t_x, t_y, t_z: x, y, z translation (bounding box 기준)
t'_x, t'_y, t'_z,: x, y, z translation (img 전체 기준)
t_z를 조절해서 (a)와 (b)를 서로 같은 선상에 놨다면 focal point의 변화에 맞춰 t_x, t_y, t_z translation을 t'_x, t'_y, t'_z로 변환 시켜준다.
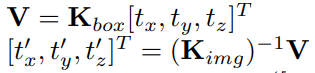
다음과 같이 식을 놓고 풀면 t'을 구할 수 있다.
3. global pose 구하기 (x, y, z rotation)
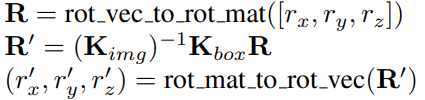
R: rotation matrix
r_x, r_y, r_z: x, y, z rotation (bounding box 기준)
r'_x, r'_y, r'_z,: x, y, z rotation (img 전체 기준)
마찬가지 방법으로 전체 이미지에 대한 rotation도 구하면 되는데 Rodrigues rotation formula를 사용하여 rotation matrix와 vector사이의 변환을 하고 2번과 똑같은 방식을 사용하면된다.
사족이지만 official 코드상으로는 opencv를 사용하여 rodrigues rotation의 compact representation을 사용하게 되어 있었다.

결과적으로 이와 같은 과정을 통해 Global pose h^img를 얻을 수 있다.
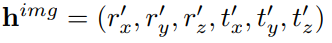
Global to local pose conversion
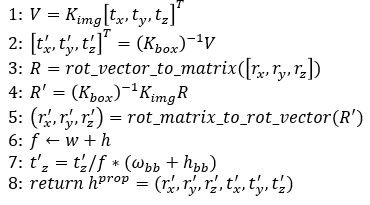
train시에 모델이 예측한 local pose와 Ground truth로 주어진 global pose사이의 loss를 계산하기 위한 global to local pose conversion도 마찬가지 방식으로 진행되기 때문에 자세한 설명은 생략한다.
6DoF to bounding box (Bounding box projection)

6DoF의 경우 영상 상에서 얼굴의 rotation과 translation 정보를 전부 포함하고 있기 때문에
이를 알면 standard한 3D facial landmark cooridnates를 영상 위에 projection할 수 있고
본 논문에서는 그렇게 projection한 landmark x, y 좌표의 최소값과 최대값을 기준으로 bounding box를 만드는데 예측한 roll에 따라 이마의 방향을 추정하여 heuristic하게 0.3배 확장함으로써 bounding box를 만든다.
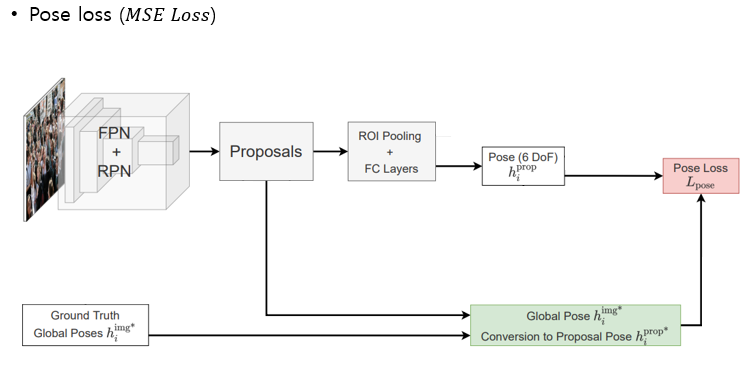
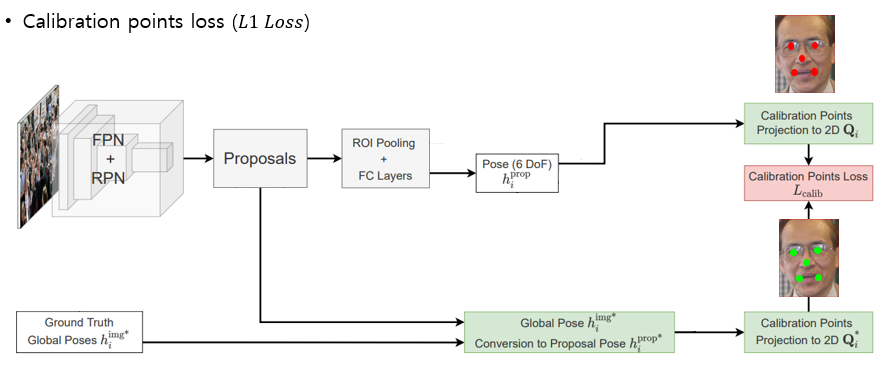
Loss
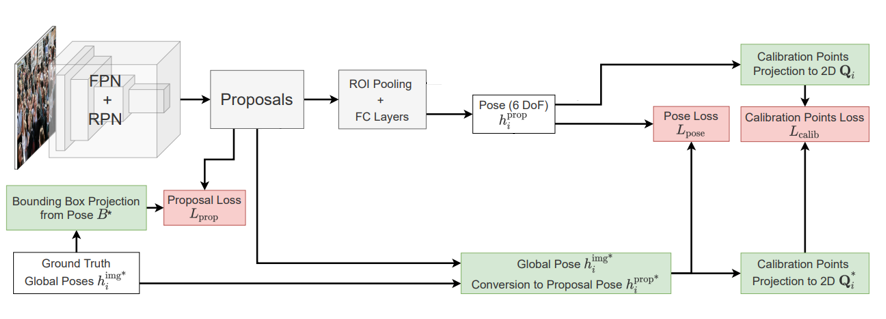
Loss 는 크게 3가지 파트로 구성된다 face인지 아닌지를 판별하는 objectness loss와 상기 설명한 방식으로 GT 6DoF pose로 standard facial landmark를 projection해서 만들어진 bounding box와 RPN에서 제안한 proposal과 비교하는 bounding box projection loss로 구성된 Proposal loss
예측한 Local 6DoF와 local pose로 conversion한 GT 6DoF를 비교하는 Pose loss
예측한 Pose를 사용하여 standard한 facial landmark 를 projection한 결과와 GT Pose를 사용하여 projection한 landmark끼리 비교하는 Calibration point loss로 구성된다.
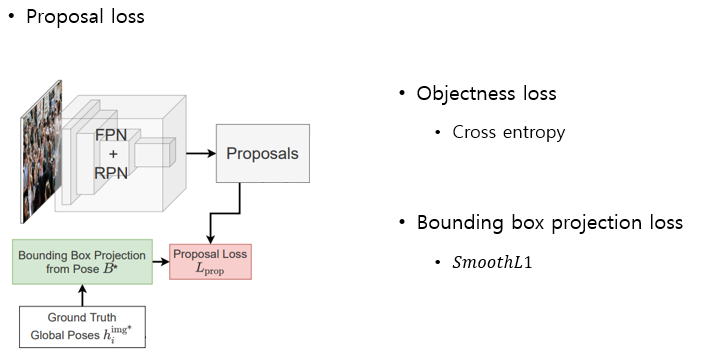
Inference time
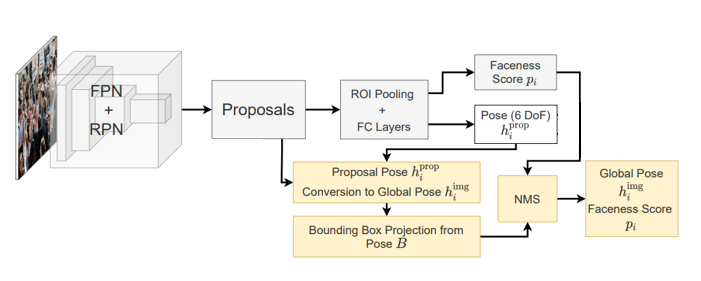
inference time에는 예측한 local 6DoF를 global pose로 전환한 뒤에 bounding box projection을 하고 RPN에서 나온 Objectness score를 Faceness score로 그대로 사용해서(어짜피 Face인지 아닌지 분류이므로)
일반 faster RCNN기반 detection 모델처럼 NMS를 하여 사용한다.
즉 모델 output은 faceness score와 6DoF만 사용된다.
- 번외
Generate ground truth 6DoF pose by using PnP algorithm
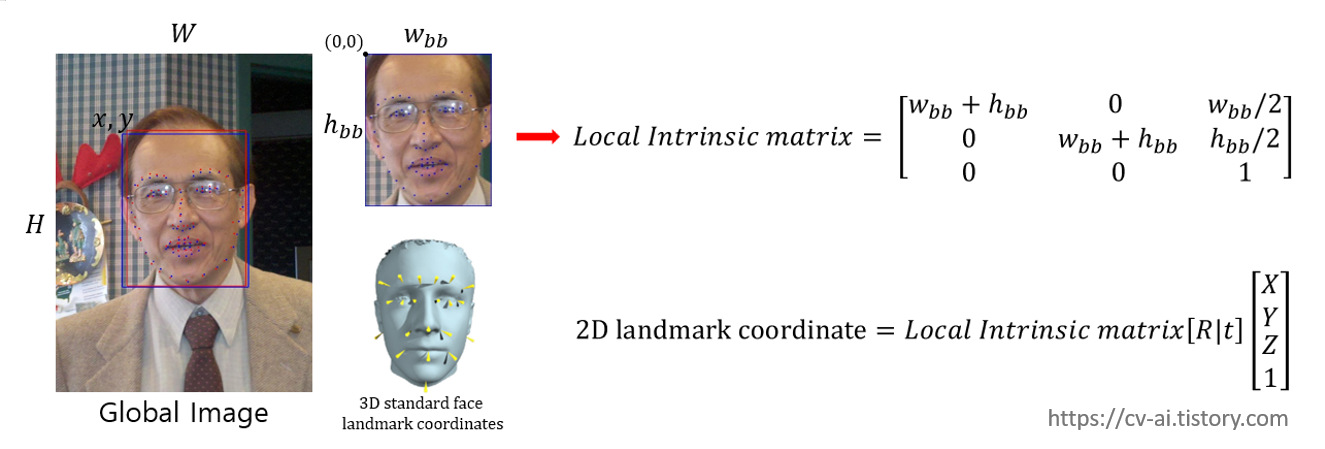
본 논문에서 나름 재밌는 점 중에 하나가 WiderFace dataset의 경우 원래 pose label 정보가 제공되지 않는데도 불구하고 WiderFace에 대한 성능평가가 진행됬다는 점이다.
어떻게 그럴 수 있었는지 간단히 언급하고 넘어가면
우선 제공되는 WiderFace에서 기본적으로 제공되는 bounding box annotation을 기준으로 이미지를 crop했다고 생각했을 때 crop된 이미지의 intrinsic matrix를 구할 수 있다.(Local Intrinsic matrix)
다음으로 standard한 human face 3d landmark coordinate를 가지고 2d landmark coordinate로 projection한다고 했을 때 img2pose에서 제공하는 2d landmark annotation과 projection한 landmark를 비교하여 둘이 일치하게 만들어주는
extrinsic matrix [R|t]를 추정할 수 있고 (위 슬라이드의 밑의 식) rotation R을 rodrigues rotation formula를 사용하여 rotation vector로 표현을 하고 translation과 같이 표현하면
이럴수가! 놀랍게도 2D landmark annotation과 standard한 3d facial landmark 만으로 6DoF를 만들 수있다.
이렇게 구한 local 6DoF pose를 global pose로 바꿔서 label로 활용한다.
이런 방식처럼 PnP알고리즘을 통해서 pose를 만들어 활용하는 방식은 얼굴처럼 어느정도 형태가 정형화된 객체에 대해서 landmark annotation을 얻을 수 있는 경우 나름 유용하게 사용할 수 있을거 같다.
장점
6DoF가지고 어지간한건 다할수있다 landmark도 찾을 수 있고(3D landmark projection해서), bounding box도 만들 수 있다.
당연한 얘기겠지만 확실히 작은 얼굴에 억지로 68개의 landmark를 찾는거 보다는 그냥 pose를 직접 예측하고 projection하는게 성능이 잘나오긴한다.
의문
기본적으로 detection process없이 바로 pose를 estimation한다고는 하는데 2-stage method기준으로 앞에 RPN에서 proposal을 이미 넘겨주는데 큰 의미가 있을까 싶다...
아무래도 z거리(depth) 같은 경우 얼굴 크기에 따라 측정에 에러가 있는거 같다.
예를 들어 어린아이랑 어른이랑 같은 영상상 depth에 있는 경우에 어린아이처럼 어른보다 머리가 좀더 작은 경우 z거리가 좀더 멀리 있다고 측정된다 (PnP로 pose를 만든 WiderFace의 경우 더 심하다)
'Paper_review' 카테고리의 다른 글
| Deep Equilibrium Models (DEQ) 리뷰 (0) | 2024.09.20 |
|---|---|
| Object-Centric Learning with Slot Attention (Neurips 2020) (0) | 2024.04.24 |
| Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions ,CVPR 2022 (0) | 2023.06.06 |
| papers (0) | 2022.09.07 |

