
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- CIL
- Img2pose
- Face Pose Estimation
- requires_grad
- state_dict()
- Facial Landmark Localization
- Energy-based model
- VQ-diffusion
- Markov transition matrix
- VQ-VAE
- img2pose: Face Alignment and Detection via 6DoF
- Mask-and-replace diffusion strategy
- ENERGY-BASED MODELS FOR CONTINUAL LEARNING
- Vector Quantized Diffusion Model for Text-to-Image Synthesis
- mmcv
- Mask diffusion
- L2P
- DualPrompt
- CVPR2022
- Class Incremental Learning
- prompt learning
- learning to prompt for continual learning
- Continual Learning
- Face Alignment
- PnP algorithm
- learning to prompt
- Discrete diffusion
- 베이지안 정리
- timm
- Class Incremental
- Today
- Total
Computer Vision , AI
StyleGAN 본문
기존 연구 및 문제점
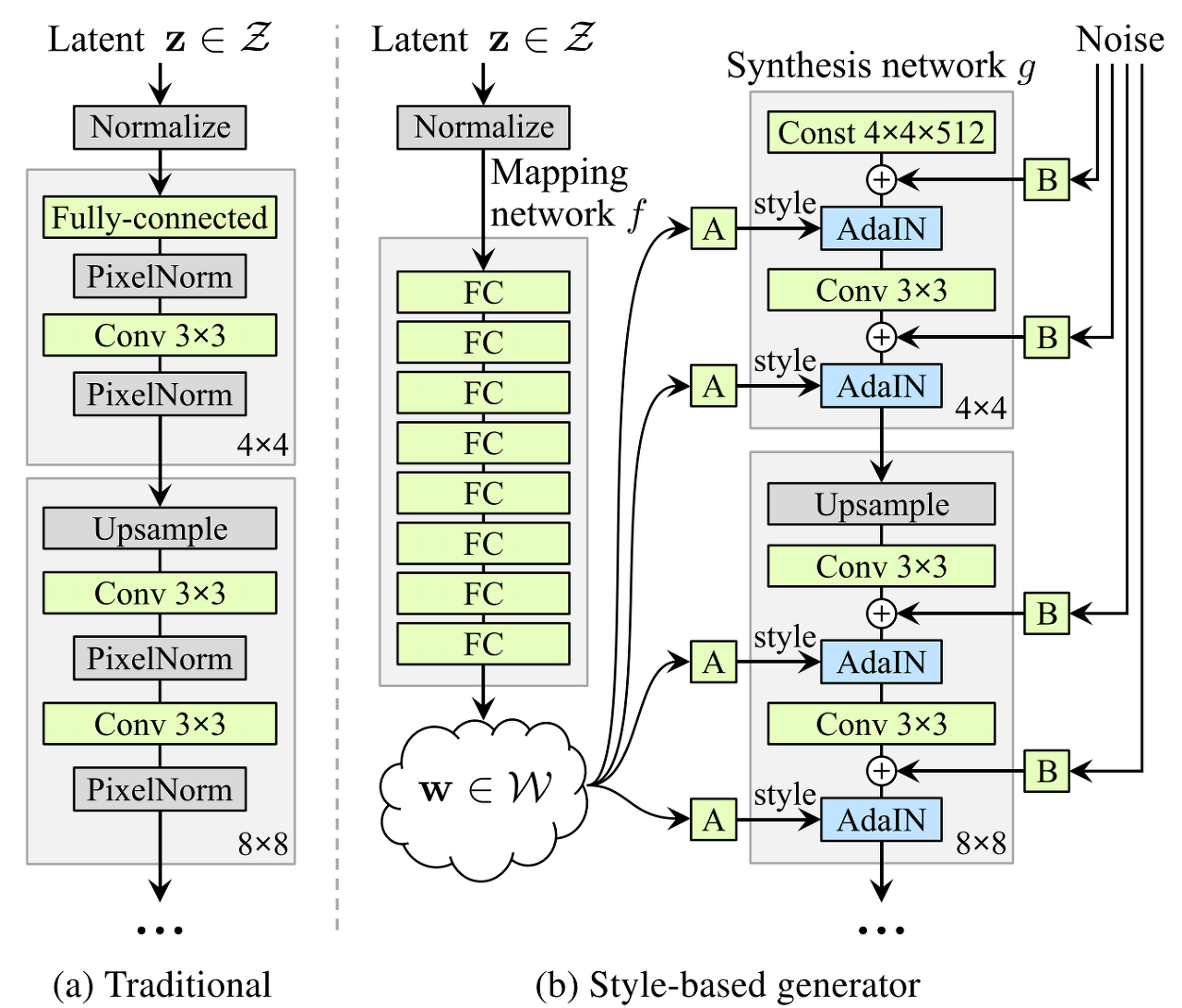
Traditional한 PGGAN (Fig1.a) 같은 경우 latent vector z를 모델에 입력으로 넣어서
점점 upsampling을 진행하며 이미지를 생성함
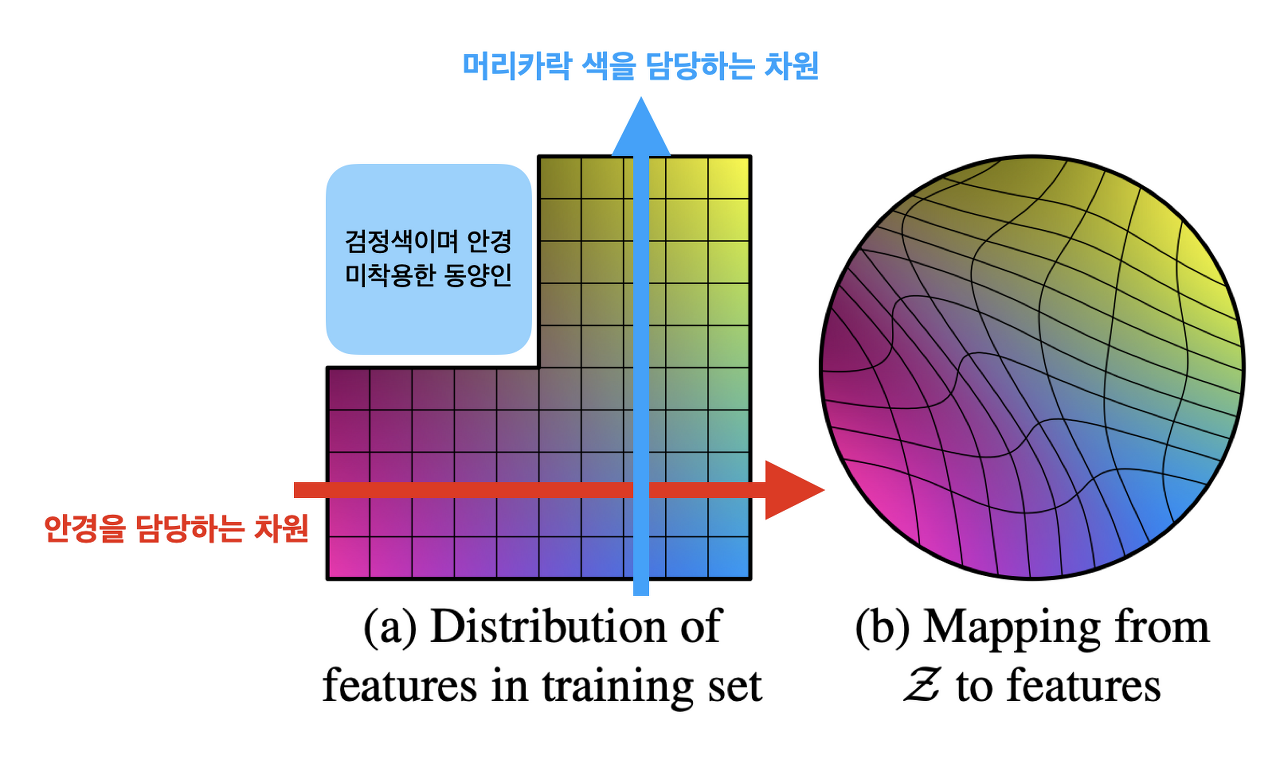
이런 latent variable 기반 모델들은 직접적으로 noise z를 넣어서 latent space에 어떻게든 매핑시키다 보니까 학습 데이터셋의 확률 분포랑 비슷하게 latent space가 형성되버림(Fig2.b) 문제는 이게 썩 좋지만은 않을 수 있음
이런 경우 문제점
-> latent space가 entangle하게 됨 (각 특징들끼리 서로 얽혀있어서 분리가 되지 않음)
이렇게 되면 학습 데이터에 없는 데이터 분포를 생성하기 어려워짐
ex) 안경을 쓴 사람, 동양인 둘다 학습을 해서 안경쓴사람과 동양인을 생성할 수 있는데
학습데이터에 안경을 안쓰면서 동양인인 사람이 없을 시 두 특징을 동시에 갖는 사람을 생성하기 힘들어짐
어떻게든 매핑하려고 하면 wrapping이 발생해서 갑자기 머리색이 막 변화하거나 안경이 이상해지거나 조금만 latent space상에서 이동해도 이상한 결과가 나옴 (Fig2.b)
해결방법
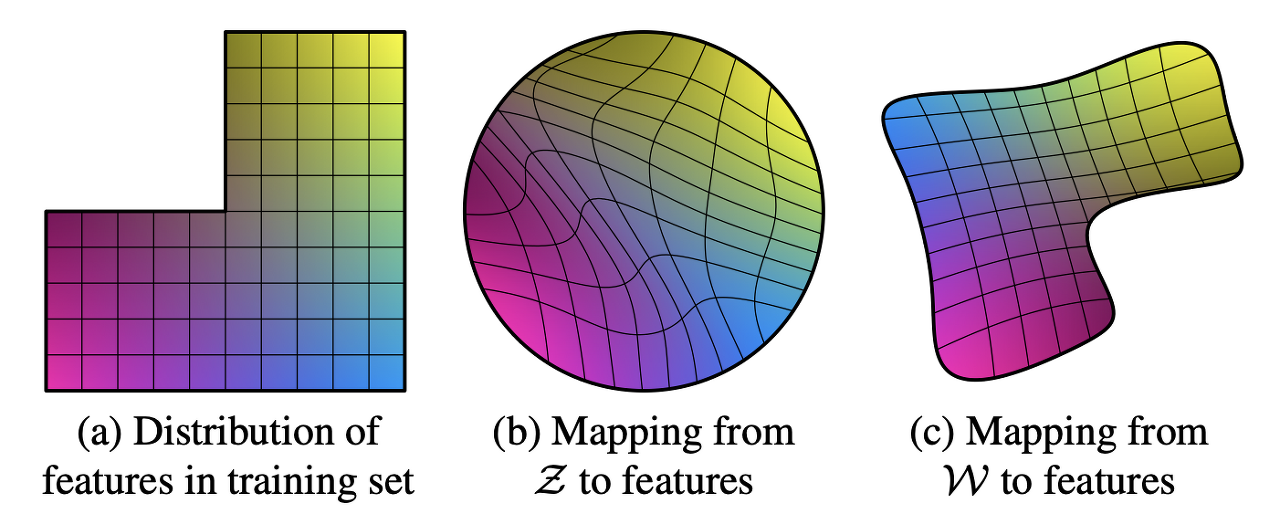
그래서 StyleGAN(b) 같은 경우 latent vector z를 바로 모델에 입력으로 넣어주지 않고 z를 train dataset 확률분포랑 비슷한 W space상으로 매핑해주는 non linear한 모델(Fig1.b) 하나 만들어놓고
forwarding하여 W space상의 w vector를 style로써 stage별 AdaIN layer의 scale값으로 넣어주게 됨 (이때 W shape을 맞춰주기 위해 affine transform 진행)
각 AdaIN layer마다 W가 하나씩 따로 들어감으로 하나의 style이 각 scale에서만 영향을 끼칠 수 있도록 분리해줌
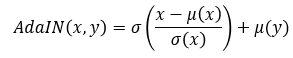
요약
1. latent z를 그대로 가져다 쓰면 z를 어떻게든 training dataset의 확률분포에 매핑시키려고 하고
그렇게 되는 경우 style끼리 entangle되기도 하고 training dataset에 없는 방향으로 style변경시 wrapping이 발생할 수 있음
-> latent z 를 완벽하진 않아도 어느정도 training dataset의 확률분포랑 비슷한 W space로 보내버리고 거기서 w vector를 style로 mapping시키기
2. 여러개의 z를 뽑아서 Mapping network를 통과시켜 만든 w vector들은 synthesis network의 '각각의' AdaIN layer에 style로써 들어가는데 식의 의미를 생각해보면
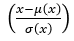
feature map상에서 'x'의 평균과 표준편차로 standardization을 해줘서 기존 feature map x가 가지고 있는 style을 제거함
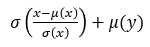
style이 제거되고 남은 content에 y즉 w vector의 평균과 표준편차를 입혀줌
각 AdaIN layer마다 w vector를 사용함으로써 scale별로(적용되는 AdaIN layer의 위치에 따라 receptive field가 다 다르니까) style이 disentagle되어 학습된다.
2-1. Style mixing: latent space에서 여러개의 latent z를 뽑아 그걸로 여러개의 w를 만들어서 네트워크를 학습시켜야 style correlation이 안일어남(ex: z1,z2 가지고 w1,w2만들어서 encoding이랑 decoding에 각각 사용하기) -> why?? 다양한 style w로 학습하게 되서?
3. Perceptual path legth를 사용하여 style이 disentangle됐나를 확인함
pretrain된 VGG16에 latent z를 넣었을때랑 e를 더해 조금 변화를 시킨 z+e를 넣었을때 feature map사이의 거리를 재서 크게 변화하면 entangle된 것
기타.
미세 수정을 위해서는 synthesis network의 noise를 수정해주면 된다.
style 조절하는법 각 stage별로 w를 조절해주면 그 scale에 맞는 style이 잘 disentangle 됐다는 전제하에 변화함
출처 (대부분의 내용을 그대로 가져옴)
https://blog.promedius.ai/stylegan_1/
[GAN 시리즈] StyleGAN 논문 리뷰 -1편
StyleGAN은 PGGAN 구조에서 Style transfer 개념을 적용하여 generator architetcture를 재구성 한 논문입니다. 그로 인하여 PGGAN에서 불가능 했던 style을 scale-specific control이 가능하게 되었습니다.
blog.promedius.ai
'備忘錄' 카테고리의 다른 글
| timm 에러 cannot import name 'container_abcs' from 'torch._six' (0) | 2024.08.07 |
|---|---|
| MMCV 인식 불가 시 (0) | 2024.08.07 |
| [Torch] requires_grad 와 state_dict() 사이의 관계 (0) | 2024.08.06 |
| Deep learning 수학 기초 이론 [Bayes theorem편] (0) | 2022.12.26 |
