
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- requires_grad
- VQ-diffusion
- CIL
- Energy-based model
- prompt learning
- Discrete diffusion
- Img2pose
- Class Incremental
- Mask-and-replace diffusion strategy
- Vector Quantized Diffusion Model for Text-to-Image Synthesis
- Face Pose Estimation
- PnP algorithm
- VQ-VAE
- DualPrompt
- Markov transition matrix
- ENERGY-BASED MODELS FOR CONTINUAL LEARNING
- CVPR2022
- Face Alignment
- img2pose: Face Alignment and Detection via 6DoF
- L2P
- learning to prompt for continual learning
- learning to prompt
- Facial Landmark Localization
- Mask diffusion
- Class Incremental Learning
- state_dict()
- 베이지안 정리
- Continual Learning
- mmcv
- timm
Archives
- Today
- Total
Computer Vision , AI
[One-page summary] Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions (CVPR 2022) by Nguyen et al. 본문
Paper_review[short]
[One-page summary] Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions (CVPR 2022) by Nguyen et al.
Elune001 2024. 1. 15. 21:53● Summary: Template-based new object and occlusion robust 3D pose estimation by contrastive learning
● Approach highlight
-
Local representation(Unseen object performance): masking global feature with binary template mask M to solve the problem of unseen object's cluttered backgrounds

-
Occlusion mask(Occlusion robustness): use a similarity-based occlusion mask O instead of a pooling layer to preserve important information

● Main results
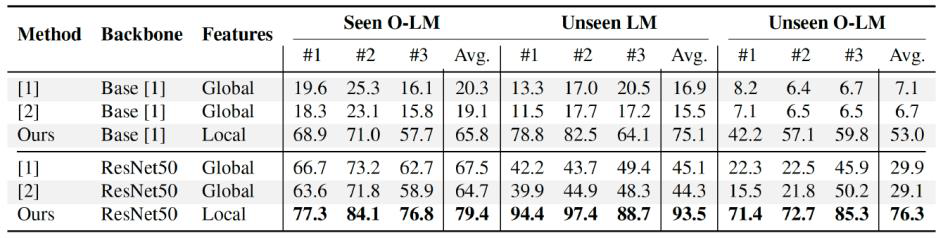

● Discussion
- Acc15 can't catch fine grained pose errors.
- I guess it is still a poor performance compared to the SoTA pose estimation model.
'Paper_review[short]' 카테고리의 다른 글
'Paper_review[short]' Related Articles
more



